生成式人工智能一日千里。
这个速度真是快得让人眼花缭乱啊!
正因应了网友们常说的,“日日工业革命,夜夜文艺复兴”啊!
一觉醒来,新闻铺天盖地:
3 月 1 日消息,阿里巴巴研究团队近日发布了一款名为“EMO(Emote Portrait Alive)”的 AI 框架,该框架号称可以用于“对口型”,只需要输入人物照片及音频,模型就能够让照片中的人物开口说出相关音频,支持中英韩等语言。
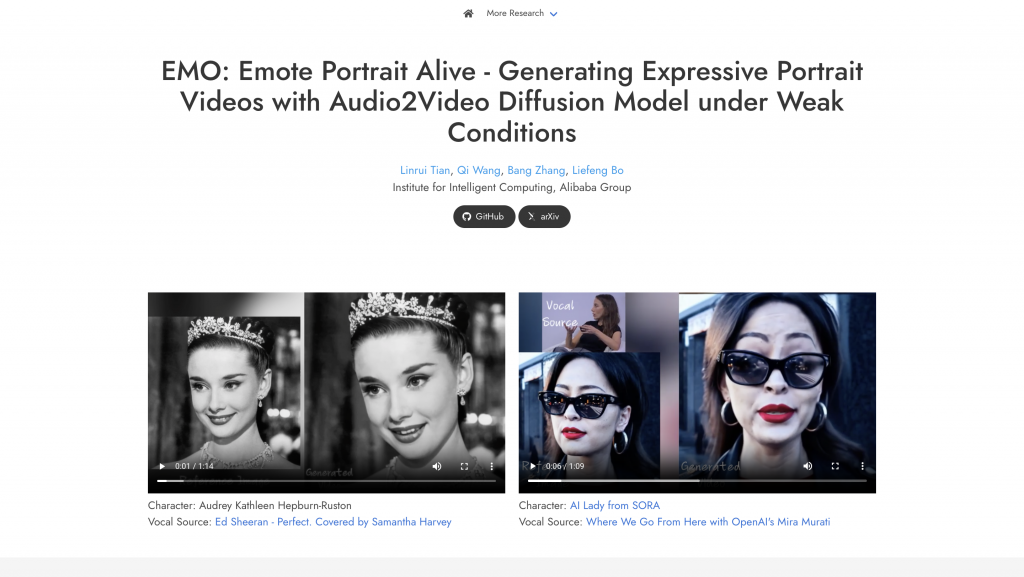
据悉,此次阿里巴巴推出的EMO 基于英伟达的 Audio2Video 扩散模型打造,号称使用了超过 250 小时的专业视频进行训练,从而得到了相关 AI 框架。
用户只需要提供一张照片和一段任意音频文件,EMO 即可生成会说话唱歌的 AI 视频,以及实现无缝对接的动态小视频,最长时间可达 1 分 30 秒左右。表情非常到位,任意语音、任意语速、任意图像都可以一一对应。
据介绍,EMO可以生成具有表情丰富的面部表情和各种头部姿势的声音头像视频,同时,其可以根据输入音频的长度生成任意持续时间的视频。
根据网络上的相关资料显示,该框架工作过程分为两个主要阶段,研究人员首先利用参考网络(ReferenceNet)从参考图像和动作帧中提取特征,之后利用预训练的音频编码器处理声音并嵌入,再结合多帧噪声和面部区域掩码来生成视频,该框架还融合了两种注意机制和时间模块,以确保视频中角色身份的一致性和动作的自然流畅。
目前,EMO框架仅用于学术研究和效果演示,仍需进一步完善和扩展。
该技术可应用于对话、唱歌等领域,但也可能成为造假利器,需谨慎使用。
目前,EMO框架上线到GitHub中,相关论文也在arxiv上公开。
GitHub:https://github.com/HumanAIGC/EMO
论文:https://arxiv.org/abs/2402.17485
此前,自留地君曾推介过一款,名叫D-ID 的应用。这个 D-ID:用你自己的照片生成视频。
不过, D-ID所生成的视频长度受限,而且视频中由照片所生成的视频中面部表情略显不自然不够流畅。

今日周六,继续加班审读学生论文